저번 교육때 찾아서 본 책인데 이제서야 시간 날때 보게 되었다. 데이터 분석을 위한 SQL 레시피라는 책인데, 안에 내용도 상당히 좋고 내가 예저에 고민했던 로그 데이터 엔지니어링 관련된 부분이기도 하고 말이지. 문제는 이 책이나 무척이나 불친절하고 실습할 수 있는 환경도 없다는 점이었다.
아, 그래서 무료로 Hive Query 공부를 사용했던 사이트를 추천한다.
https://demo.gethue.com/hue/home
Hue - SQL Editor
Let anybody query, write SQL, explore data and share results.
demo.gethue.com
위의 사이트는 무료이나, 중간중간에 세션이 자주 끊긴다. Visual Code에 코드를 저장하고 여기에서는 실행만 하는 것을 권장합니다. 오라클의 경우 https://livesql.oracle.com/apex/f?p=590:1000 사이트가 있습니다.
책에서는 Postgre SQL을 비롯한 다양한 SQL을 지원하지만, 제가 실무적으로 많이 사용했던 것은 Hive와 Impala이므로 여기서는 기본적으로 Hive를 기준으로 쿼리를 준비하도록 하겠습니다. 참고로 위의 Hue 사이트의 ID와 Password는 화면에 지원되므로 바로 로그인해서 쿼리 작성이 가능합니다. 책에서는 별도의 쿼리를 제공하지 않으므로 제가 아는 범위 내에서 작성해서 공유하도록 하겠습니다.
01. 로그 데이터 테이블을 생성합니다.
02. 일단 데이터가 제대로 들어갔는지 봐야겠죠?

데이터가 생각했던데로 들어갔다는 것을 확인이 가능하다.
03. 로그 데이터에서 호스트를 분리해 보자.

04. 그러면 이번에는 path와 id를 나눠봅시다.
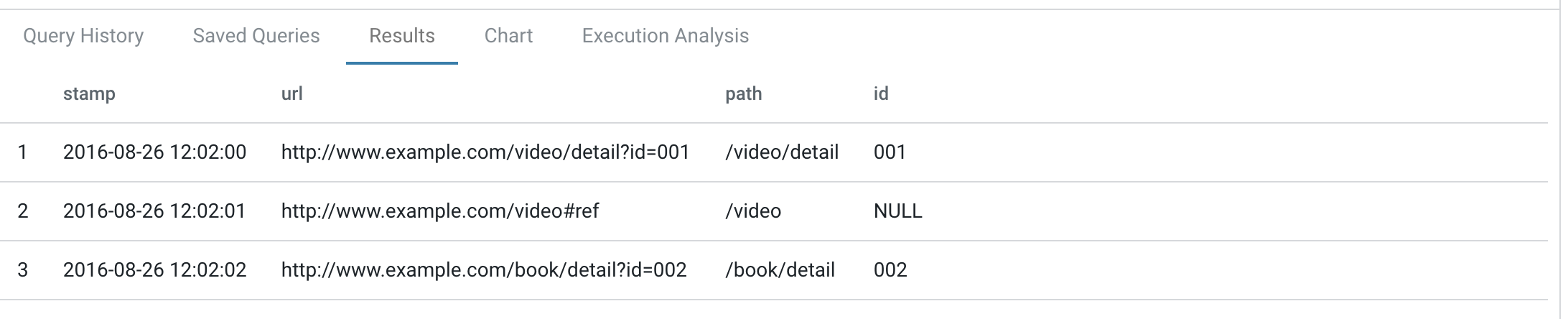
오라클에서 할때에는 정규표현식 작성하느라 무척이나 고생했는데, 여기서는 간단하게 함수 하나로 끝나기 때문에 무척이나 편리합니다.
이전 회사에서는 데이터 엔지니어링 도움을 받을 수 없었기 때문에 분석을 하거나 모델을 만들기 위해서는 개인이 열심히 쿼리를 공부해서 데이터를 정제하고 이를 기반으로 보고서를 만들거나 분석툴을 이용해서 다른 작업을 해야 했습니다. 그러나 새로운 회사에서는 기본적인 쿼리를 작성하고 데이터 엔지니어링 팀을 지원을 요청하면 상당히 많은 부분 도움을 받을 수 있었습니다. 실제로 업무 이외에 이러한 기술 분석을 하기 위한 환경과 데이터가 충분히 존재한다는 것을 감사하고 있다.
시간 날때마다 쿼리 작성하고 결과 파일 정리해서 올리도록 하겠습니다. Visual Code를 복사해서 붙여넣기 하면 저렇게 예쁘게 나오는 구나. 이런 자료가 다른 사람에게도 도움이 되겠지만, 아마 가장 많은 도움이 되는 것은 내가 아닐까 싶다.
'Hive, Impala, Spark' 카테고리의 다른 글
| Impala table create and insert from csv file (0) | 2023.04.24 |
|---|---|
| 경우의 수를 생성하는 Oracle 쿼리 (0) | 2022.11.03 |
| Oracle connect by (0) | 2022.06.17 |
| Oracle connect by (0) | 2022.05.25 |
| Impala random sampling (0) | 2022.04.29 |