python pandas를 몇 개월 사용하면서 느끼는 점은 SAS에 비해서 문서화가 아주 잘 되어 있고 pandas 사이트에 가보면 정말 잘 정리된 설명서가 있다. 내가 파이썬을 오래 쓰지는 않았지만 최근에 SAS를 Python으로 변환하는 작업을 해보면서 data handling을 정말 극한까지 하는 것을 배우고 있다. 기존에 R을 이렇게 했더라면 정말 대학원에서 날고 기지 않았을까 생각을 할 정도로 열심히 하고 있다. 이게 다 회사가 갑자기 망해서 이직을 준비하면서 속도를 내게 된 것이다.
Python dataframe에서는 개별 코드에서 컬럼을 변경하거나 생성하는 것을 가급적 추천하지 않는다. 그래서 많이 쓰이는 것이 바로 pandas.assign이다. 이거를 쓰면서 코드가 SAS datastep과 많이 비슷해졌는데, 한가지 문제가 생겼다. 바로 윗줄에서 만들었던 컬럼을 다음 다른 컬럼을 만들면서 사용하지 못한다는 것이다. SAS에서는 원래 잘 되었고 sql에서는 calculated라는 것이 있지만 pandas에서는 찾기가 쉽지 않았다. 아니, 사실 영어만 좀 하고 차분히 글을 읽어보면 python pandas assign() 설명문 맨 마지막줄에 있는 내용을 금방 이해했을 것이다.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.assign.html
pandas.DataFrame.assign — pandas 1.2.5 documentation
The column names are keywords. If the values are callable, they are computed on the DataFrame and assigned to the new columns. The callable must not change input DataFrame (though pandas doesn’t check it). If the values are not callable, (e.g. a Series,
pandas.pydata.org
오늘 오후에 내 피같은 시간 30분을 날리면서 고민했던 것인데, 설명문에 아주 친절하게 lambda로 해결하면 된다고 나왔는데 제대로 보지 않았던 것이다. 정말 파이썬의 경우 영어를 잘 하면 설명문을 보면서 정말 많은 도움이 될 수 있을 것이라고 생각된다. 아래는 pandas.assign()안에서 이전에 정의했던 컬럼을 다음 컬럼 만들때 참조해서 만드는 것이다. 오늘 오후에 이거를 몰라서 기존에 짜던 코드를 다시 3개로 쪼개는 삽질을 했다. 현재 변환하는 코드가 상당히 많은데 날 잡아서 예전에 짜놨던 초창기 코드를 좀 가다듬어야할 필요성이 있다. 아래는 lambda를 이용해서 만들어본 코드. 코드는 정말 생각보다 시간날 때, 짜보고 테스트 해보는게 장땡이라고 생각이 든다.
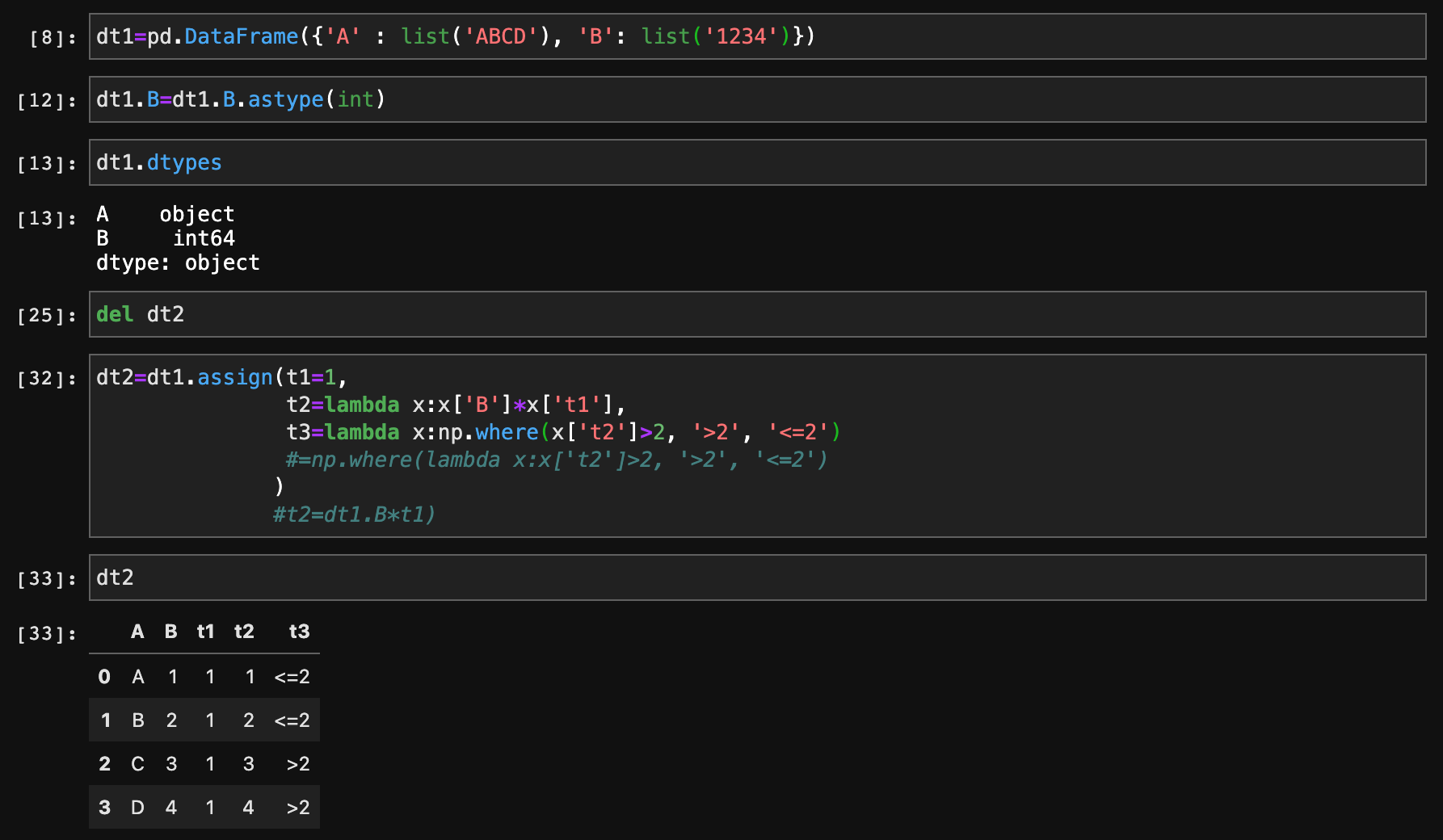
사실 오늘 오후에는 이제 왠만한 것들은 다 할줄 안다고 생각했는데, 이제 보니까 이런 기본적인 것도 할줄 몰랐다는 생각이 드니까 좀 많이 창피하더라.
'Python, PySpark' 카테고리의 다른 글
| Python : CSV 쪼개기 (0) | 2021.09.08 |
|---|---|
| SAS retain equivalent in Python (0) | 2021.08.22 |
| Pseudo SAS Retain in Python (0) | 2021.06.18 |
| Python Pandas column name 일괄 변경 (0) | 2021.06.07 |
| Python Pandas SQL like function (0) | 2021.06.02 |